1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
| import requests,re,csv
def getpage(url):
headers={
'User-Agent':"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.5112.81 Safari/537.36 Edg/104.0.1293.54"
}
response=requests.get(url,headers=headers)
if response.status_code==200:
return response.text
print("爬取失败")
return None
def parsehtml(html):
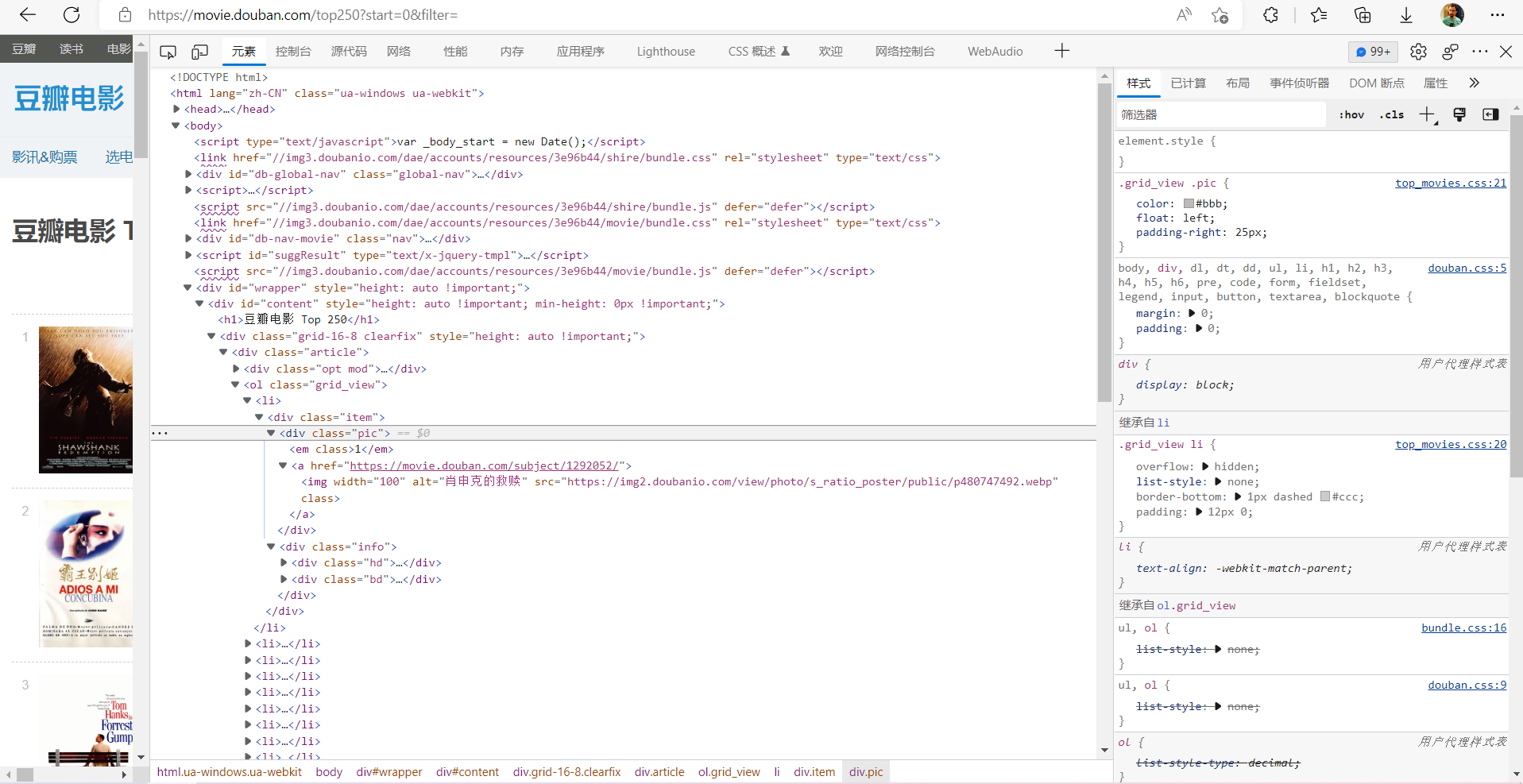
pattern=re.compile(
'<div class="item">.*?<em class="">(.*?)</em>.*?<span class="title">(.*?)</span>.*?<br>(.*?) / .*? / (.*?)</p>.*?property="v:average">(.*?)</span>',re.S)
items=re.findall(pattern,html)
return items;
def write(items):
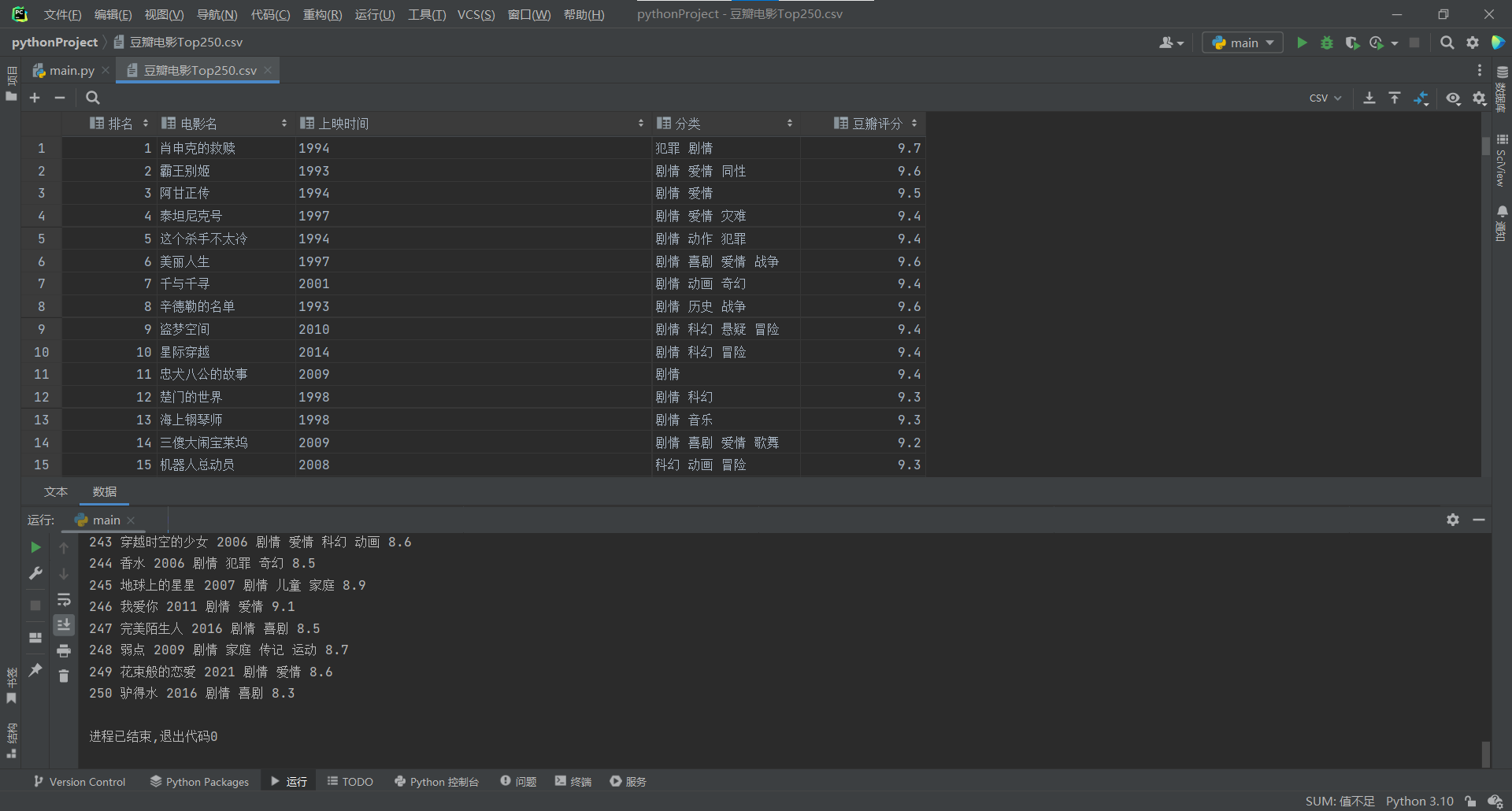
with open("豆瓣电影Top250.csv",mode="w", encoding="utf-8-sig", newline="") as f:
writer = csv.writer(f)
headerList=['排名','电影名','上映时间','分类','豆瓣评分']
writer.writerow(headerList)
for i in items:
tmp=[]
tmp.append(i[0])
tmp.append(i[1])
tmp.append(str(i[2]).strip())
tmp.append(str(i[3]).strip())
tmp.append(str(i[4]).strip())
print(tmp[0],tmp[1],tmp[2],tmp[3],tmp[4])
writer.writerow(tmp)
def main():
items=[]
for i in range(0,250,25):
url='https://movie.douban.com/top250?start={}&filter='.format(i)
text=getpage(url)
items+=parsehtml(text)
write(items)
main()
|