爬虫基础
HTTP 基本原理
参考资料:
URI 和 URL
URI: 统一资源标识符
URL: 统一资源定位符
URN: 统一资源名称
现在互联网,URN 用得很少,一般网页链接🔗称为 URL
超文本
网页源代码 HTML 称为超文本
HTTP 和 HTTPS
HTTP: 超文本传输协议
HTTPS:HTTP 下加入 SSL 层
HTTP 请求过程
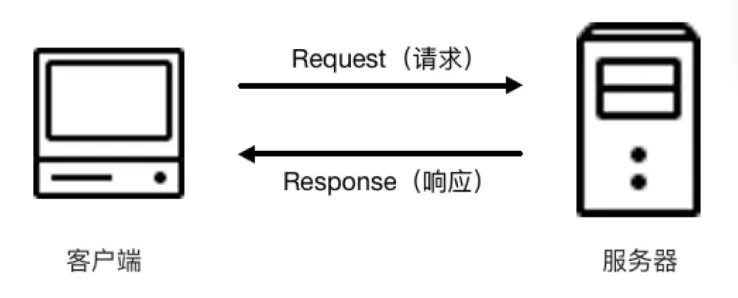
我们利用浏览器” 检查 “工具的网络来观察这个过程
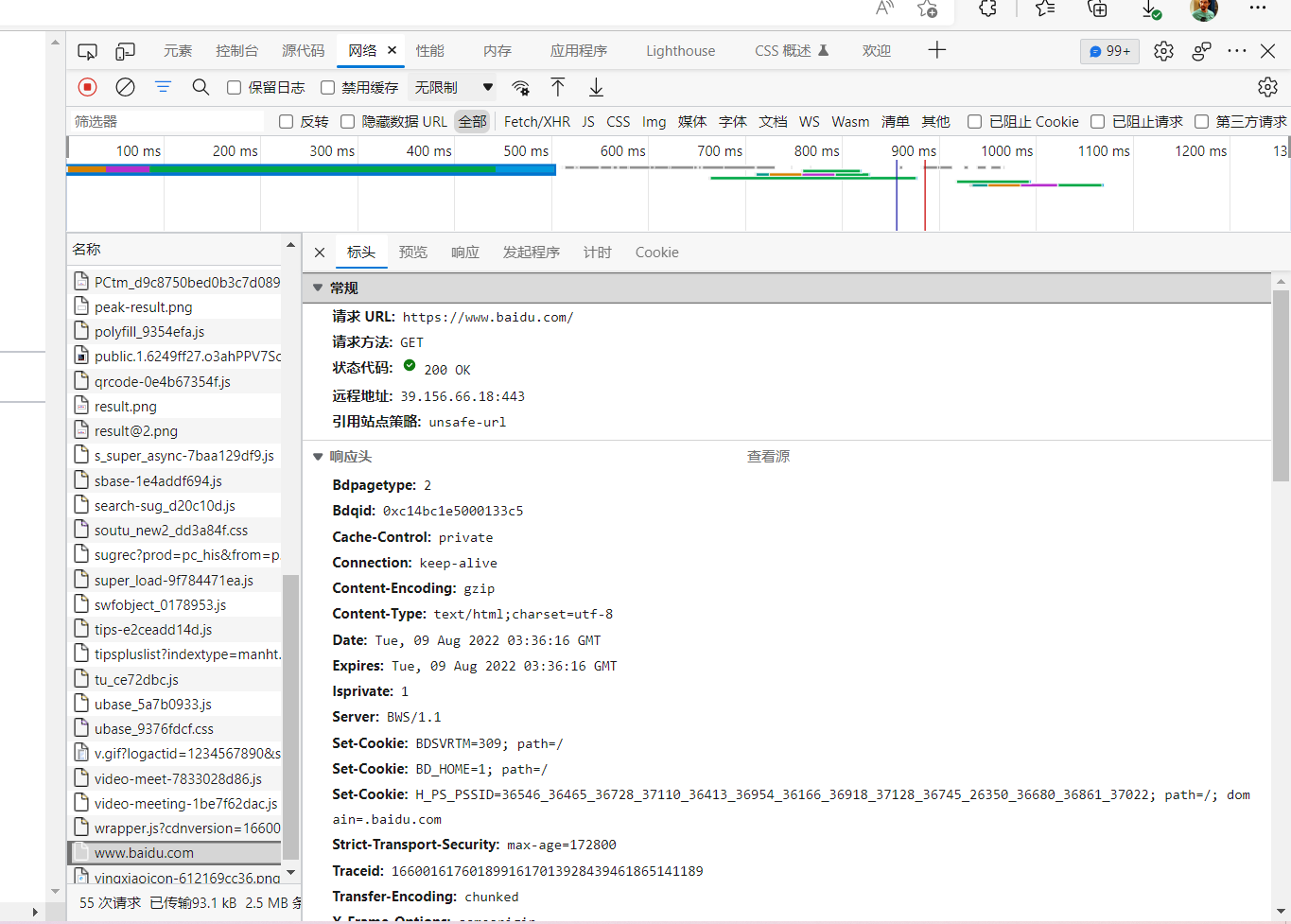
General 部分
Request URL: 请求的 URL
Request Method: 请求方法
Status Code: 响应状态码
Remote Address: 远程服务器的地址和端口
Referrer Policy:Referrer 判别策略
Response Header: 响应头
Request Header: 请求头
请求
请求由客户端发出,分为 4 部分
请求方法: Request Method
请求网址: Request URL
请求头: Request Headers
请求体: Request Body
请求方法
常见的为:GET 和 POST
GET 与 POST 区别
GET 的参数在 URL 里面,而 POST 请求的数据以表单传输,包含在请求体
GET 的数据只有 1024 字节,而 POST 没有限制
其他请求方法

请求的网址
请求的网址即 URL
请求头
Accept: 请求报头域,指定客户端接收哪些类型的信息
Accept-Language: 指定客户端可接受语言类型
Host: 指定请求资源的主机 IP 和端口
Cookie: 储存在用户本地终端上的数据, 特定的 web 文档关联在一起, 保存了该客户机访问这个 Web 文档时的信息, 当客户机再次访问这个 Web 文档时这些信息可供该文档使用。
Referer: 标识请求是从那个页面发过来的
User-Agent: 一个特殊字符串头,使得服务器能够识别客户使用的操作系统及版本、CPU 类型、浏览器及版本、浏览器渲染引擎、浏览器语言、浏览器插件等。
Content-Type: 内容类型,一般是指网页中存在的 Content-Type,用于定义网络文件的类型和网页的编码,决定文件接收方将以什么形式、什么编码读取这个文件
请求体
请求体承载的是 POST 的表单数据,对于 GET,请求为空
响应
响应状态码
常见的 HTTP 状态码:
- 200 - 请求成功
- 301 - 资源(网页等)被永久转移到其它 URL
- 404 - 请求的资源(网页等)不存在
- 500 - 内部服务器错误
其它可以参考 HTTP 状态码 | 菜鸟教程
响应头
响应头包含服务器对请求的应答信息,如 Content-Type、Sever、Set-Cookie
响应体
响应体包含响应的正文数据
网页基础
网页组成
网页是由 HTML、CSS、JavaScript 组成
如果想学爬虫,必须要点 Web 基础