urllib 库的使用
开始
urllib 是 Python 内置的 HTTP 请求模块,其包含以下四个模块
request:HTTP 请求模块
error: 异常处理模块
parse: 工具模块,拆分、解析、合并
robotparser: 识别网站 robots.txt 文件,判断哪些网站可以爬。
请求发送
1 | import urllib.request |
data 参数
data 参数为可选,使用需要,使用 bytes () 转换为字节流编码格式
1
2
3
4
5import urllib.request
import urllib.parse
data=bytes(urllib.parse.urlencode({'B':'1'}),encoding='utf-8')
response=urllib.request.urlopen('http://httpbin.org/post',data=data)
print(response.read().decode('utf8'))
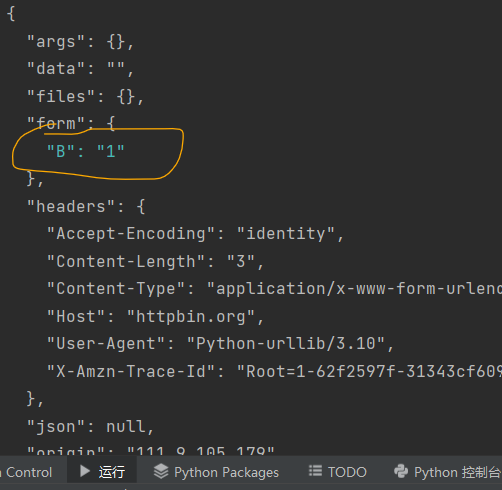
我们的数据出现在了 form 字段里,这是我们用 POST 方法传递的数据
timeout 参数
1
2
3
4
5
6
7
8import urllib.request
import socket
try:
response=urllib.request.urlopen('http://www.google.com',timeout=1)
print(response.read().decode('utf-8'))
except urllib.error.URLError as e:
if isinstance(e.reason,socket.timeout):
print('TIME OUT')
Request()
urllib.request — Extensible library for opening URLs — Python 3.10.6 documentation
Request 能实现更多参数的请求
1
2
3def __init__(self, url, data=None, headers={},
origin_req_host=None, unverifiable=False,
method=None):URL: 请求 URL
data: 必须为 bytes (),如果是字典可以用 urllib.parse.urlencode()
headers: 为一个字典
origin_req_host:表示这个请求是否是无法验证的
method: 请求方法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18from urllib import request,parse
url='http://httpbin.org/post'
headers={
'Host':'httpbin.org',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.5112.81 Safari/537.36 Edg/104.0.1293.47'
}
dict={'b':1}
data=bytes(parse.urlencode(dict),encoding='utf8')
data=bytes(parse.urlencode({'B':'1'}),encoding='utf-8')
req=request.Request(url,data=data,headers=headers,method='POST')
"""
另一种请求头的添加方式
req=request.Request(url=url,data=data,method='POST')
req.add_header('Host','httpbin.org',)
"""
response=request.urlopen(req)
print(response.read().deco
进阶用法
Handler
现在我们介绍 Handler
比如:
HTTPDefaultErrorHandler: 用于处理响应错误,错误会抛出 HTTPError 类型的异常
HTTPRedirectHandler: 处理重定向
HTTPCookieProcesser: 处理 Cookies
ProxyHandler: 设置代理,默认代理为空
HTTPPasswordMgr: 用于管理密码,维护了用户名和密码
HTTPBasicAuthHandler: 用于管理认证
Cookies
1 | import http.cookiejar,urllib.request |
1 | import http.cookiejar,urllib.request |
1 | import http.cookiejar,urllib.request |
异常处理
URLError
1 | from urllib import request,error |
HTTPError
1 | from urllib import request,error |
URLError 是 HTTPError 的父类
1 | from urllib import request,error |
解析链接
urlparse
1 | from urllib.parse import urlparse |
urlunparse()
1 | from urllib.parse import urlunparse |
urlsplit
1 | from urllib.parse import urlsplit |
urlunsplit()
1 | from urllib.parse import urlunsplit |
urljoin()
1 | from urllib.parse import urljoin |
urlencode
在 GET 中加参数
1 | from urllib.parse import urlencode |
parse_qs()
反序列化
1 | from urllib.parse import urlsplit,parse_qs |
quote()
将内容转为 URL 编码
1 | from urllib.parse import quote,urljoin |
unquote()
1 | from urllib.parse import quote,urljoin,unquote |
Robots 协议
robotparser()
set_ur():设置 Robots.txt 链接
read():读取 robots.txt 并分析
parse():解析 robots.txt 文件
can_fetch():传入 User-Agent 和 URL, 判读是否可爬取
mtime():返回上次抓取的时间
modified():设置当前时间为上次抓取时间
1 | from urllib.robotparser import RobotFileParser |